Transkript:
Mein Name ist Michael Tegtmeier, und ich habe einen Hintergrund in der Physik. Ich habe bei Senvion gearbeitet und mich auf verschiedene Messungen konzentriert. Ich habe viele Daten analysiert und festgestellt, dass Hersteller trotz einer Fülle von Sensoren und Daten nicht wirklich auf die Art und Weise analysieren, wie es heute möglich wäre – insbesondere mit KI. Das wurde mir besonders im Jahr 2017 deutlich.
Heute möchte ich vorstellen, was wir bisher entdeckt haben, und einen Blick auf den aktuellen Stand der Windindustrie werfen. Am wichtigsten ist, dass ich die potenziellen Vorteile erörtern werde, die KI für Anwendungen in der Windenergie bringen kann, sowie einen Ausblick geben, wohin sich die Dinge in den nächsten fünf Jahren entwickeln könnten.
Ich werde also über die Möglichkeiten von KI sprechen – nicht nur im Allgemeinen, sondern auch speziell im Bereich der Windenergie. Ich werde über den Mehrwert sprechen, den sie bietet, und warum die Richtung der KI-Entwicklung entscheidend ist. Es ist allgemein bekannt, dass Machine Learning und Big Data zu Schlagwörtern geworden sind, aber ich werde versuchen zu erklären, warum sie wichtig sind.
In den letzten Jahren gab es drei wesentliche Fortschritte im Bereich KI, und einer der wichtigsten ist das Training von KI auf großen Datensätzen, um zu verstehen, wie diese Daten zusammenhängen. Zum Beispiel gebe ich in den Chat ein: „Sie sind der technische Betreiber einer Windenergieanlage. Am Hauptlager einer älteren Anlage ist ein Schaden aufgetreten, der durch eine erhöhte Temperatur angezeigt wird. Schreiben Sie eine E-Mail an das Serviceteam mit der Bitte, so schnell wie möglich eine Ölprobe aus dem Lager zu entnehmen, und tun Sie dies bitte innerhalb von 300 Zeichen."
Das Ergebnis war eine gut formulierte Nachricht, die zeigt, dass Prozesse wie das Verfassen einer E-Mail bereits effektiv automatisiert werden können. Auf einer leichteren Note kann KI auch Bilder generieren. Zwar hatte das generierte Bild einer Windturbine vier Rotorblätter – eine kleine Abweichung –, aber es verdeutlicht dennoch die Möglichkeiten von KI.
Dies führt uns zum zweiten Fortschritt: der Objekterkennung, die enorme Mengen an Messdaten oder beschrifteten Datensätzen erfordert. Dies hat eine breite Anwendung, insbesondere beim autonomen Fahren, aber auch für Startups und Unternehmen, die mit KI Blattschäden oder Risse an Türmen erkennen.
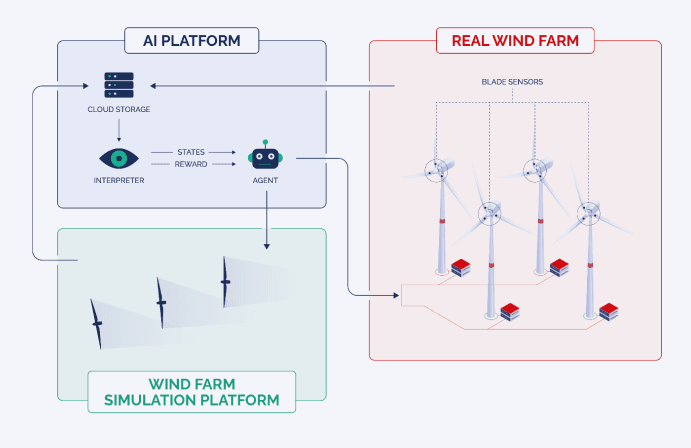
Heute möchte ich einen anderen Ansatz vorstellen, der sich auf Reinforcement Learning konzentriert. Es handelt sich um einen Algorithmus, der besonders gut darin ist, das Spielen komplexer Spiele zu erlernen. Die Idee hierbei ist, dass ein KI-Agent sein Verhalten in einer Umgebung gemäß einer bestimmten Zielfunktion anpassen kann, selbst wenn er die Umgebung nicht kennt. Dieses Konzept ist auch auf eine Windenergieanlage sehr gut anwendbar.
Die Vorteile des KI-Einsatzes lassen sich bereits recht gut aufzeigen. Bevor wir jedoch darauf eingehen, sollten wir besprechen, warum dies relevant ist und welche Probleme es adressiert. Mit zunehmender Größe der Windturbinen stehen wir vor spezifischen Herausforderungen. Bei einem Repowering-Projekt beispielsweise ist es kein großes Problem, wenn eine von 50 Turbinen ausfällt. Aber nach dem Repowering, wenn ich 17 wesentlich leistungsstärkere Turbinen habe und eine davon ausfällt, sind das Risiko und der Ertragsverlust viel größer.
Mit zunehmender Größe der Turbinen steigt auch die physische Belastung, die auf sie einwirkt, was sie empfindlicher und anfälliger für Störungen macht. Hinzu kommen der Fachkräftemangel und der demografische Wandel: Wer wird all die notwendigen Aufgaben erledigen? Darüber hinaus neigen Original Equipment Manufacturers (OEMs) dazu, diese Risiken aus ihren Büchern in Vollwartungsverträge zu verlagern, was sie großzügiger macht – mit der Folge, dass Opportunitätskosten aus Ertragsverlusten in den Bilanzen der Betreiber landen.
Wenn es beispielsweise ein Problem mit der Trafostation oder einer Turbine in einem Windpark mit 17 Turbinen gibt, können die Kosten aus Ertragsverlusten aufgrund langer Lieferzeiten schnell in die Millionen gehen. Wenn man all diese Schäden zusammenzählt und auswertet, welche Schäden zu einem Ertragsverlust führen können, kommt man auf ungefähr 26.000 Euro pro Megawatt pro Jahr durch Ausfallzeiten. Wenn sich das mit Software ändern lässt, hat man einen guten ROI erzielt.
Hier ist eine Grafik mit Schadensstatistiken. Auf der y-Achse ist die Wahrscheinlichkeit des Schadenseintritts dargestellt, und die Blasengröße repräsentiert die Ausfallzeit, wenn der Schaden eintritt. Der entscheidende Punkt ist, dass wir viele Ereignisse, die zu Ausfallzeiten führen und derzeit in den Bilanzen der Betreiber stehen, verhindern können.
Sehen wir uns ein Praxisbeispiel an. Wir haben einen Betreiber und einen OEM gewarnt, dass ein Generator kurz vor dem Ausfall stand. Der Temperaturtrend ist hier dargestellt, aber unsere Warnung wurde ignoriert. Als die Turbine einen Totalausfall erlitt, wurde der Betrieb der anderen zwei Turbinen, die ähnliches Verhalten zeigten, angepasst, um dasselbe Schicksal zu verhindern. Was ich hier hervorheben möchte: Störungen können Monate im Voraus erkannt werden. Das gibt Ihnen Zeit, den Austausch von Komponenten zu planen und die Ausfallzeit erheblich zu reduzieren.
Hier ist ein weiteres Beispiel. Es wurde ein Foto von schwarzem Fett an einer Turbine aufgenommen – es war ursprünglich weiß. Einige Wochen später haben wir eine Warnung ausgegeben, obwohl wir keine erhöhte Temperatur im Rotorlager festgestellt hatten. Einfache präventive Maßnahmen können ergriffen werden, was Eric, glaube ich, später besser erläutern wird.
Das Ganze fällt unter den Oberbegriff Machine Learning und Big Data. Wir nehmen historische Daten und trainieren ein neuronales Netz auf der Grundlage vergangener Verhaltensweisen. Wir wissen, wie gut wir das können, weil wir Datensätze aus den Trainings- und Validierungsdatensätzen verwenden, die es uns ermöglichen, Temperaturvorhersagen mit einer Genauigkeit von +/- 0,5 Grad und Leistungsvorhersagen mit einer Genauigkeit von +/- 30 kW zu treffen.
Wir nehmen Außentemperatur, Windgeschwindigkeit und Windrichtung als Eingangsparameter, um die Leistungsabgabe einer Turbine vorherzusagen. Wir können dann sehr präzise Vorhersagen über das Leistungsverhalten machen und so kleinere Abweichungen, Pitch-Probleme oder Probleme im Steuerungssystem identifizieren. Wir können Dinge erkennen, die vorher nicht sichtbar waren.
Hier sehen Sie, dass die Leistungskurve nicht dem Standard des Herstellers entspricht, sie wurde jedoch mit einer Simulation verglichen. Kleine Abweichungen sind deutlich sichtbar. Unten sehen Sie den Unterschied zwischen der Simulation und den tatsächlichen Daten.
Nun ist ein entscheidender Aspekt, was mit all diesen Berichten über Anomalien, hohe Temperaturen usw. zu tun ist. Wenn ich ein Portfolio von mehreren hundert Turbinen habe, ist es unmöglich, alles zu überprüfen. Was wir tun, ist, ständig Feedback von unseren Kunden über die Relevanz dieser Alarme zu sammeln. Mit der Zeit entsteht ein vorhergesagter Relevanzscore mithilfe eines 1- bis 5-Sterne-Bewertungssystems. In diesem Beispiel stieg der Relevanzscore, bevor der Algorithmus ein Problem markierte, was die Wirksamkeit dieses Systems zeigt.
Der Algorithmus hat also erkannt, dass er aufpassen muss. Er hat etwas hier als relevant eingestuft. Das ist hervorragend für die Priorisierung innerhalb großer Portfolios und zur Identifizierung, welche Ereignisse unsere Aufmerksamkeit erfordern.
Der „Heilige Gral", sozusagen, ist die Fehlermodus-Vorhersage, was diesen Vortrag zur Schadensklassifizierung besonders spannend macht. Am Ende möchte ich eine Analyse – nicht immer manuell durchgeführt, sondern vorzugsweise automatisiert – die mögliche Ursachen aufzeigt, wie beispielsweise eine Leistungsminderung.
Ich habe jedoch nicht immer alle notwendigen Informationen. Ich habe möglicherweise einige Statuscodes, aber diese können schwierig zu interpretieren sein. All das zuzuordnen ist eine enorme Arbeit. Was wir hier tun, ist, die Daten unserer Kunden oder die Anomalien, die unser Erkennungssystem identifiziert, mit Labels zu versehen. Anschließend geben wir eine Wahrscheinlichkeitsschätzung ab, wie ein zukünftiger Kunde sie wahrscheinlich labeln würde.
In diesem Fall sehen wir Verbesserungspotenzial, aber wir sehen bereits in Orange den Anstieg jedes Patches, was als erster Hinweis äußerst spannend ist. Wahrscheinlich müssen wir uns keine Gedanken über den Patch machen.
Lassen Sie uns einen Moment über unsere KI-Infrastruktur sprechen, die wir in vier Stufen entwickelt haben. Wir glauben, dass sich das System im Laufe der Zeit weiter verbessern wird. Die erste Stufe umfasst klassisches Data Engineering, bei dem Rohdaten untersucht und analysiert wird, wie sie gewonnen werden können. In der zweiten Stufe bereinigen wir die Daten mithilfe von KI-Methoden oder statistischen Methoden. Dann definieren wir in der dritten Stufe den Trainingsdatensatz für die Anomalieerkennung. All das ist Teil der Anomalieerkennungsstufe, bei der wir traditionelle neuronale Netze und andere statistische Methoden zur Ausreißererkennung verwenden.
Transfer Learning ist besonders wichtig. Manchmal haben wir nicht viele Daten, und so lernen wir aus größeren Datensätzen. Wenn beispielsweise ein Windpark neu gebaut wurde, habe ich noch keine Daten, benötige aber trotzdem ein Monitoring. Wir lernen also vorab von benachbarten Anlagen oder ähnlichen Typen und trainieren das System dann schnell, um zu verstehen, wie diese neue Anlage funktioniert.
Die dritte Stufe, die vielleicht die wichtigste ist, umfasst die Klassifizierung oder Fehlermodus-Vorhersage. Wir verwenden hier eine weitere KI-Schicht, die alle verfügbaren Daten, Statuscodeunterschiede, Anomalien und alles andere, was wir finden können, einbezieht, um diese Vorhersage zu treffen.
Nichts davon würde funktionieren, wenn der Prozess des Kunden oder das Feedback des Serviceteams nicht stimmen würde. Daher haben wir viel Zeit und Mühe investiert, um diesen Prozess zu differenzieren. Die entscheidende Frage bei Tausenden von Anlagen ist: Wie können wir das skalieren? Die Priorisierung der Alarme mittels KI ist entscheidend, und ein weiteres wichtiges Thema, das wir in der Zusammenfassung besprechen sollten, ist: Wie bringt man den Servicepartner dazu, die Ereignisse tatsächlich zu verbessern oder sogar Maßnahmen an der Anlage einzuleiten?
Vertrauen in die Daten und die Sicherstellung einer niedrigen False-Positive-Rate sind wichtig. Wir streben danach, schnell zu sein – einen Alarm innerhalb von 36 Stunden zu versenden. Wir tun dies anlageweise. Zum Beispiel haben wir 4.000 Netze in Produktion und erhalten im Durchschnitt 120 Alarme pro Woche, die von Kunden gelabelt werden. Das hat uns eine Fülle von Erfahrung in der Fehlererkennung verschafft.
Wohin führt das alles? Ich habe hier einen alten Zeitungsartikel mitgebracht. Er berichtet von Mathematiklehrern, die sich Sorgen machten, als Taschenrechner eingeführt wurden, aus Angst, ihre Stellen zu verlieren. Natürlich wissen wir, dass das nicht passiert ist – es gibt immer noch Mathematiklehrer, aber die Lehrmittel und -methoden haben sich verändert. Ähnlich verändern sich auch Berufsbilder. Die Rolle des technischen Betreibers beispielsweise verändert sich schneller, als wir vielleicht denken, aber sie verschwindet nicht – das ist wichtig zu betonen.
Welche Veränderungen sehe ich voraus? KI-gestützter Betrieb wird Realität sein, wobei KI empfiehlt, worauf man sich konzentrieren oder welche Maßnahmen man ergreifen sollte. Gleichzeitig werden übergeordnete Entscheidungen mit Tools unterstützt, die abwägen, ob es sich lohnt, ein Serviceteam zu schicken oder nicht. Es ist unerlässlich, stets eine menschliche Aufsicht zu gewährleisten, insbesondere wenn erhebliche Kosten im Spiel sind.
Ein weiteres großes Thema ist Big Data. Wir müssen weg von 10-Minuten-Datenintervallen und hin zu 60-Sekunden- oder sogar sekundengenauer Daten. Es stecken viel mehr Informationen und Präzision darin, und es kann die Granularität des Monitorings verbessern. Wenn ich beispielsweise ein Azimut überwache, das hin und her oszilliert, werde ich in 10-Minuten-Intervallen nichts sehen. Wenn ich aber die Lebensdauer des Azimutmotors berechnen möchte, muss ich mir Minutendaten ansehen.
In den nächsten fünf Jahren glauben wir, dass Anlagen in Echtzeit gesteuert werden. Das bedeutet, dass wir Dinge berücksichtigen können wie: Wenn eine Komponente vollständig defekt ist und der Marktstrompreis derzeit niedrig ist, können wir die Leistung reduzieren. Wenn ich hingegen abends einen guten Marktstrompreis habe und weiß, dass ich eine Störung habe, könnte ich die Leistung nachmittags reduzieren und mit maximaler Leistung laufen, wenn der Marktpreis und die Windbedingungen gut sind.
Wir können Agenten einsetzen, die lernen, diese sich ständig verändernden Faktoren wie Verbrauch und Marktstrompreise in Echtzeit zu managen. Diese Trends sind auch offshore bemerkbar, wo bereits viele Kunden und Projekte stattfinden. Großprojekte, die offshore stattfinden, werden auch onshore stattfinden. Mehr Verantwortung fällt dem Betreiber statt dem OEM zu, aufgrund der damit verbundenen großen Risiken, und Serviceverträge werden weniger umfassend.
Die Automatisierung von Prozessen und Entscheidungen, auch mit KI, ist offshore bereits gang und gäbe.
Vielen Dank für Ihre Zeit!