Transfer Learning ist eine ML-Technik, die das aus vortrainierten Modellen für ähnliche Aufgaben gewonnene Wissen nutzt, um die Leistung bei einer neuen Aufgabe zu verbessern. Dabei werden vortrainierte Modelle übernommen, feinjustiert und auf eine neue Aufgabe mit ähnlichen Merkmalen angewendet. Transfer Learning spart Zeit und Ressourcen und steigert die Genauigkeit.
Vorteile von Transfer Learning
- Spart Zeit und Ressourcen: Vortrainierte Modelle wurden bereits auf einer großen Datenmenge trainiert, was den Bedarf an umfangreichen Daten für die neue Aufgabe reduziert.
- Verbesserte Genauigkeit: Vortrainierte Modelle haben bereits Merkmale und Muster aus den Daten gelernt, auf denen sie trainiert wurden, die zur Steigerung der Genauigkeit bei der neuen Aufgabe wiederverwendet werden können.
- Lösung von Datenmangelproblemen: Transfer Learning ist nützlich, wenn die Datenlage für die neue Aufgabe begrenzt ist, und der Einsatz vortrainierter Modelle kann helfen, dieses Problem zu überwinden.
Nachteile von Transfer Learning
- Einschränkungen für die neue Aufgabe: Vortrainierte Modelle sind möglicherweise nicht für die neue Aufgabe geeignet, wenn diese sich erheblich von der Aufgabe unterscheidet, auf der sie trainiert wurden.
- Feinjustierung erforderlich: Die Feinjustierung vortrainierter Modelle für die neue Aufgabe kann zeitaufwändig sein und erfordert domänenspezifisches Wissen.
- Einschränkungen vortrainierter Modelle: Die Genauigkeit vortrainierter Modelle hängt von der Qualität der Trainingsdaten ab, und das Modell ist möglicherweise nicht optimal für die neue Aufgabe geeignet.
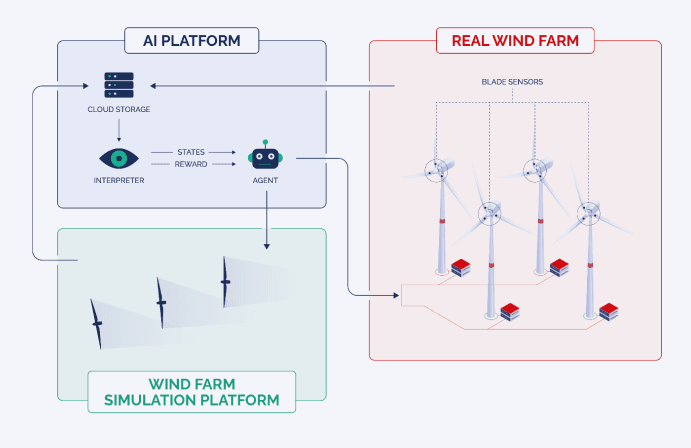
Transfer Learning mit Windturbinendaten
![]()
Transfer Learning kann auf Windturbinendaten angewendet werden, um die Leistung von Modellen zur vorausschauenden Wartung zu verbessern. Modelle zur vorausschauenden Wartung prognostizieren potenzielle Ausfälle in Windturbinen, senken Wartungskosten und steigern die Effizienz. Durch den Einsatz von Transfer Learning können Modelle auf Windturbinendaten feinjustiert werden, was die Genauigkeit erhöht und den zur Schulung des Modells erforderlichen Datenumfang reduziert.
In Fällen, in denen für eine Windturbine nur begrenzte Daten verfügbar sind, wird eine auf Transfer Learning basierende Vortrainings-Feinjustierungs-Strategie eingesetzt, um genaue Vorhersagen zu erzielen. Sind weniger als ein Jahr Daten verfügbar, wird Transfer Learning empfohlen; liegen weniger als zwölf Monate an Daten vor, ist es für eine gute Modellperformance unerlässlich. Stehen hingegen mehr als zwei Jahre Daten zur Verfügung, ist Transfer Learning nicht notwendig.
Der Transfer-Learning-Prozess umfasst zwei Schritte. Zunächst wird ein neuronales Netz mithilfe von Daten ähnlicher Turbinen vortrainiert, woraus ein generisches Modell entsteht, das das durchschnittliche Verhalten der Gruppe abbildet. Anschließend wird dieses generische Turbinenmodell mithilfe der begrenzt verfügbaren Daten einer einzelnen Turbine feinjustiert, wobei deren Besonderheiten bei der Erstellung von Vorhersagen berücksichtigt werden.
Obwohl Transfer Learning eine effektive Strategie bei begrenzter Datenlage ist, wird dennoch empfohlen, das neuronale Netz erneut zu trainieren, sobald mehr Daten verfügbar sind. Ein Nachtrainingsplan, der im ersten Halbjahr monatliches Nachtraining, im zweiten Halbjahr zweimonatliches Nachtraining, im zweiten Jahr halbjährliches Nachtraining und ab dem dritten Jahr jährliches Nachtraining vorsieht, stellt sicher, dass ein breiteres Spektrum an Turbinenzuständen in den Trainingsdaten repräsentiert ist.
Zusammenfassend lässt sich sagen, dass Transfer Learning ein wertvolles Werkzeug für Windturbinendaten darstellt, das eine Lösung für die Herausforderung begrenzter Daten bietet und gleichzeitig die Leistung von Modellen zur vorausschauenden Wartung verbessert.
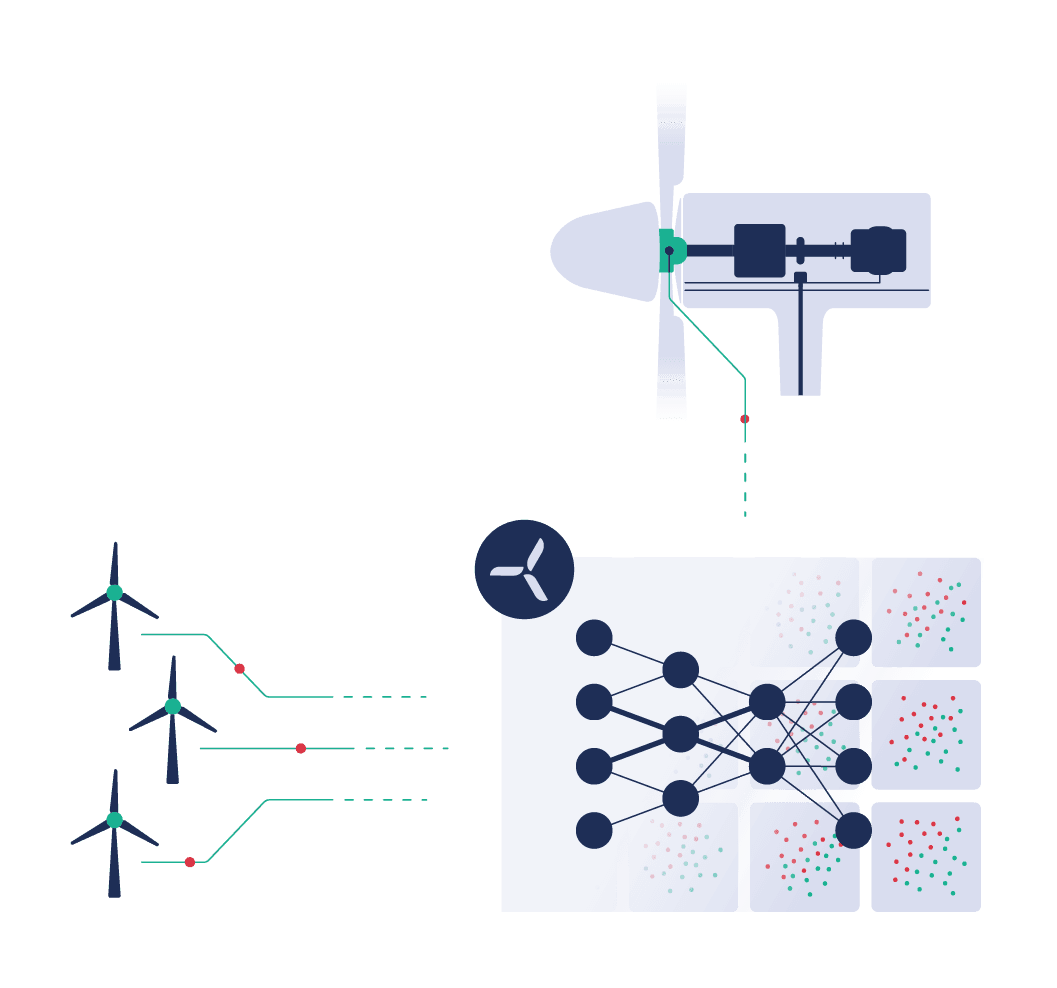
Analyse von Transfer Learning – Ergebnisse von Turbit
![]()
Um die Genauigkeit von Transfer Learning im spezifischen Anwendungsbereich von Turbit zu testen, haben wir mehrere neuronale Netze trainiert.
Im ersten Bild (ganz links) sehen Sie eine Instanz, die darauf trainiert wurde, die Leistung einer Windturbine anhand eines vollständigen Datenjahres (Windgeschwindigkeit, Umgebungstemperatur, Windrichtung) zu lernen. Dies wurde ohne Vortraining durchgeführt, und man erkennt, dass die Ergebnisse mit einer durchschnittlichen Abweichung von 140 kW nicht optimal sind.
Im zweiten Bild (Mitte links) sieht man eine trainierte Instanz, die ausschließlich mit Vortraining von ähnlichen Turbinen erstellt wurde. Die Vorhersagen werden sehr genau, sind jedoch in einigen Fällen weit daneben.
Im dritten Bild (Mitte rechts) sieht man die vortrainierte Instanz, feinjustiert mit einem Monat Daten aus dem Januar. Die Vorhersagen sind sehr genau, und die Ausreißervorhersagen treten nicht mehr auf (absolut keine False Positives).
Im vierten Bild sieht man, wie das Training auf lediglich einem Monat Daten abgeschnitten hätte. Dies war überraschend gut, jedoch lässt sich mit großer Wahrscheinlichkeit annehmen, dass diese Instanz in anderen Jahren nicht gut performen wird, insbesondere bei unerwarteten Höchsttemperaturen.
Turbit hat viele weitere dieser Tests (Cross-Validation) durchgeführt und ist zu folgendem Ergebnis gelangt:
„Transfer Learning ist immer eine gute Option und macht Vorhersagen robuster und genauer – ist aber nicht in jedem Fall notwendig."